5. Why Deep Learning Works
Deep Learning Performs Epistemic Reduction

A math-free computer-science-free description of why Deep Learning works.
We have now built a base of theory for
Why AI Works, what Models are and how to create them, what Reductionism and Holism are, and what the process of Reduction is. These are the fundamentals of AI Epistemology. This base allows us to discuss various strategies to move towards Understanding Machines in a well understood and controlled manner.
We are now ready to discuss why Deep Learning (DL) works. This is the fifth and last entry in the AI Epistemology Primer.
Deep Learning Performs Reduction
This is an unsurprising claim, considering the preceding chapters. There are several mutually compatible theories for “how” Deep Learning works. But just as in the first chapter, we will now discuss the Epistemological aspects, “why” it works, from several viewpoints and levels, starting from the bottom. We will use examples from the TensorFlow system and API (as a library) as a stand-in for all Deep Learning-family algorithms and TF programs, because the available API functions heavily shape and constrain solutions that can be implemented in this space and the generalization should be straightforward enough.
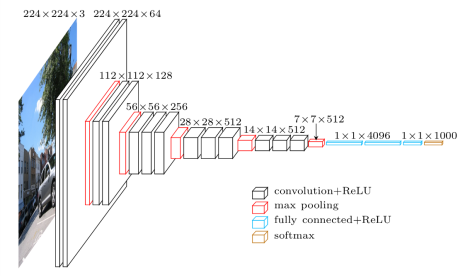
Consider the following illustration of image Understanding using Keras (an excellent abstraction layer on top of TensorFlow):
I like to refer to the input layer as being “on the bottom” rather than at the far left as in this image. When viewing it my way, the low-to-high dimension we use in my rotated version of the above can be mentally mapped to a low-to-high stack of abstraction levels; I’m not the only one using this dimension this way. I hope this rotation isn’t too confusing.
We can see that there is an obvious data Reduction and an obvious complexity Reduction. Can we determine whether the system is also performing what I’d like to call “Epistemic Reduction”: Is it reducing away that which is unimportant, and if so, how does it accomplish this? How does an operator in a Deep Learning stack know what makes something important (Salient)?
A pure data “reduction” of sorts could be accomplished by compression schemes or even random deletion. This is undesirable. We need to discard the non-salient parts so that in the end, we are left with what is salient. Some people have not understood the importance of Salience based Reduction and use lossless compression power of reversible algorithms as a measurement of intelligence. Which is no more useful than believing a simple video camera can understand what it sees.
So let me conjure up, a bit like in the movie “Inside Out”, a fairytale of what goes on in a Deep Learning network, except we’ll do it “Bottom Up”. Suppose we have built a system for finding faces in an image, with the intent of incorporating that as a feature in a camera; many cameras have this feature already, so this is not a far-fetched example. We implement an image understanding neural network, show the system many kinds of images for a few days, perhaps using so-called supervised learning in order to improve this story, and then we show it an image of a family having a picnic in a park and ask the system to outline where the faces are so that the camera can focus sharply on them.
The input image is converted from RGB color values to an input array and the data in this array is then shuffled through many layers of operators. And for many of these layers, there are fewer outputs than there are inputs, as you can see in the above diagram. Which means some things have to be discarded by the processing. Each layer receives initially signals “from below”, i.e. from the input, or from lower levels of abstraction, and produces some reduced output to send to the next layer operator above.
To continue the tale, at some early level, some operator is given a few adjacent pixels and determines that there is a vertical, slightly curved line dividing a darker green area from a lighter green area, so it “tells” the operator above this simpler line/color based description using some encoding we don’t really care about.
The operator at the level above might have gotten another matching curve and says “these match what I saw a lot of when the label “blade of grass” was given as a ground truth label during (supervised) learning. If no label is known, then we again assume some other uninteresting representation. It is OK to propagate results without human-labeled signals because whatever signaling scheme is used will be learned by the level above.
The operator above that says “when I get lots of blades-of-grass signals I reduce all of that to a “lawn” signal as I send it upward.
And eventually we reach the higher operator layers and someone there says “We are a face finder application. We are completely uninterested in lawns” and discards the lawn as non-salient.
What remains after you discard all non-faces are the faces.
You cannot discard anything until you know what it is, or can at least estimate whether it’s worth learning. Specifically, until you understand it at the level of abstraction you are operating at. The low level blade-of-grass recognizers could not discard the grass because they had no clue about the high level saliencies of lawn-or-not and face-or-not that the higher layers specialize in.
You can only tell what’s Salient or not (important or not) at the level of Understanding and Abstraction you are operating at. Each layers receives “lower level descriptions” from below, discards what it recognizes as irrelevant, and sends its own version of “higher level descriptions” upward until we reach someone who knows what we are really looking for.
This is of course why Deep Learning is deep.
This idea itself is not new. It was discussed by Oliver Selfridge in 1959; he described an idea called “Pandemonium” which was largely ignored by the AI community because of its radical departure from the logic based AI promoted by people like John McCarthy and Marvin Minsky. But Pandemonium presaged, by almost 60 years, the layer-by layer architecture with signals passing up and down that is used today in all Deep Neural Networks. This is the reason my online handle is @pandemonica
— * —
So do any TensorFlow operators support this Reduction?
Let’s start by examining the Pooling operators; there are a few in the diagram. They are conceptually simple. There are over 50 pooling operators in TensorFlow. There is an operator named “2x2 Max-Pool Operator”. In this diagram, it is used four times:
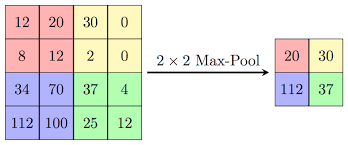
It is given four inputs with varying values and propagates the highest value of those as its only output. Close to the input layer these four values may be four adjacent pixels where their values might be a brightness in some color channel, but higher up they mean whatever they mean. In effect, the Max-Pool 2x2 discards the “least important” 75% of its input data, preserving and propagating only one (highest) value.
In the case of pixels, it might mean the brightest color value. In the case of blades of grass, it might mean “there is at least one blade of grass here”. The interpretation of what is discarded depends on the layer, because in a very real sense, layers represent levels of Reduction; Abstraction levels, if you prefer that term.
And we should now be clearly seeing one of the most important ideas in Deep Neural Networks: Reduction has to be done at multiple levels of abstraction. Each set of decisions about what is reduced away as irrelevant and what is kept as possibly relevant can only be made at an appropriate abstraction level. We cannot yet abstract away the lawn if all we know is there are dark-and-light-green-areas levels.
This is a simplification; decisions made in this manner will be heeded only if they have contributed to positive outcomes in learning. Unreliable and useless decision makers will be ignored using any of several mechanisms that we may apply during learning. More later.
For now, we continue by examining the most popular subset of all TensorFlow operators – the Convolution family. From the TensorFlow Manual:
Note that although these ops are called “convolution”, they are strictly speaking “cross-correlation”
Convolution layers discover cross-correlations and co-occurrences of various kinds. Co-occurrences to known patterns in the image at various locations; spatial relationships within an image itself, like Geoff Hinton’s recent example of the mouth normally being found below the nose; and more obviously, in the supervised learning case, correlations between discovered patterns and the available meta-information (tags, labels) that correlate with the patterns the system may discover. This is what allows an an Image Understander to tag the occurrence of a nose in an image with the text string “nose”. Beyond this, such systems may learn to Understand concepts like “behind” and “under”.
The information that is propagated to the higher levels in the network now describes these correlations. Uncorrelated information is viewed as non-salient and is discarded. In the diagram above, this discarding is done by a max pooling layer after the convolution+ReLU layers. ReLU is a kind of layer operator that discards negative values, introducing a non-linearity that is important for DL but not really important for our analysis.
This pattern of three layers — convolution, then ReLU, then a pooling layer — is quite popular because this combination is performing one reliable Reduction step. These three layer types in this “packaged” sequence may appear many times in a DL computational graph. And each of these three-layer packages is reducing away things that levels below had no chance of evaluating for saliency because they didn’t “Understand” their input at the correct level.
Again,
This is why Deep Learning is deep… Because you can only do Reduction by discarding the irrelevant if you Understand what is relevant and irrelevant at each different level of Abstraction.
Is Deep Learning Science or not?
While the Deep Learning process can be described using mathematical notation, mostly using Linear Algebra, the process itself isn’t Scientific. We can not explain how this system is capable of forming any kind of Understanding by just staring at these equations, since Understanding is an emergent effect of repeated Reductions over many layers.
Consider the Convolution operators. As the TF manual quote clearly states, Convolution layers discover correlations. Many blades of grass together typically means a lawn. In TF, a lot of cycles are spent on discovering these correlations. Once found, the correlation leads to some adjustment of some weight to make the correct Reduction more likely to be re-discovered the next round (because this Reduction is done multiple times) but in essence, all correlations are forgotten and have to be re-discovered in every pass through the Deep Learning loop of upward signaling and downward gradient descent with minute adjustments to erring variables. The system is in effect learning from its mistakes, which is a good sign, since that may well be the only way to learn anything. At least at these levels. This up-and-down may be repeated many times for each image in the learning set.
This up-and-down makes some sense for image Understanding. Some are using the same algorithms for text. Fortunately, in the text case, there are very efficient alternatives to this ridiculously expensive algorithm. For starters, we can represent the discovered correlations explicitly, using regular “pointers” or “object references” in our programming languages. Or “synapses” in brains. “This (software) neuron correlates with that software neuron” says a synapse or reference connecting this to that. We shall discuss such systems in the Organic Learning series of blog entries; coming up next.
Neither the Deep Learning family of algorithms, or Organic Learning, are Scientific in any meaningful way. They jump to conclusions on scant evidence and trust correlations without insisting on provable causality; this is disallowed in scientific theory, where absolutely reliable causality is the coin of the realm. F=m*a or go home. Most Deep Neural Network programming is uncomfortably close to trial and error, with only minor clues about how to improve the system when reaching mediocre results. “Adding more layers doesn’t always help”. These kinds of problems are the everyday reality to most practitioners of Deep Neural Networks. With no a priori Models, there will be no a priori guarantees. The best estimate of the reliability and correctness of any Deep Neural Network, or even any Holistic system we can ever devise, is going to be extensive testing. More on this later, in future blogs.
Why would we ever use engineered systems that cannot be guaranteed to provide the correct answer? Because we have no choice. We only use Holistic methods when the reliable Reductionist methods are unavailable. As is the case when the task requires the ability to perform Autonomous Reduction of context-rich slices of our rich complex reality as a whole. When the task requires Understanding.
Don’t we have an alternative to these unreliable machines? Sure we do. There are billions of humans on the planet that are already masters of this complex task. Because they live in the rich world and need skills that are unavailable with Reductionist methods, starting with low level things like object permanence. So you can replace a well-performing but theoretically unproven contraption – a Holistic Understanding Machine built out of Deep Neural Networks – with a well-performing human being using a deeply mystical kind of Understanding hidden in their opaque heads. Who earns much more per hour. This doesn’t look like much of an improvement. The machine cannot be proven correct because it doesn’t function like normal computers. It is performing Reduction, the skill formerly restricted to animals.
A Holistic skill.
My favorite soundbite is a mere corollary to the Frame Problem by McCarthy and Hayes; you have seen it and you will see it again, since it is one of the stronger results of AI Epistemology. But we will, in but a few years, agree on a definition of intelligence that makes autonomous Reduction a requirement. This once semi-heretic soundbite will then be obvious to all. If it isn’t already.
All intelligences are fallible