9. Understanding Machine One

UM1 is a cloud based REST service that provides Natural Language Understanding (NLU) as a Service (UaaS). It can be viewed as providing a "large" language Model in the style of GPT/3 and Google BERT but it currently cannot generate any language; it is strictly an Understanding Machine. And it isn't large.
If you send it some text, you will instantly get back UM1's Understanding of the text. Its Understanding may differ from yours, just like yours may differ from that of a co-worker, but will still be useful in apps requiring industrial strength NLU.
How UM1 Understands
The Understanding algorithm running in UM1 is much simpler than the Organic Learning algorithm running in the OL Learner. The Learner emits a Language Competence file designed to be loaded into a cloud based UM1 allocated to handle that language. In what follows, all learning has been done and UM1 is just using the collection of patterns in its loaded Competence to Understand any incoming "wild" text.

We first note that UM1 can read streaming text. Normally it is given text as documents ranging in size from a few characters (such as in tweets and chat messages) to larger documents such as emails. In these cases the Understanding is about the entire document and is returned when the reading has finished. API options allow clients to ask the system for per-character, per-line, or per-paragraph results, to be used with infinite streams.
Deep Learning systems (at least those of the past) split longer documents and process those in batches small enough to fit in the GPUs.

OL and UM1 are reading the text one character at a time. Parsing text into words is implementing a Language Model, and we are philosophically deeply opposed to Language Models. Also, Chinese, Japanese, and several other Asian languages do not use word separating spaces, which makes word level input difficult.
If the atomic unit of input is a word, such as in traditional NLP and even in most DL based Understanding of language, then character level morphology features such as a plural-s suffix will be "below the atomic level of the algorithm" and now would require special processing such as stemming, which discards valuable information. Instead, OL/UM1 systems are designed to learn all character level (morphology) features. DL community has started to switch to character input.
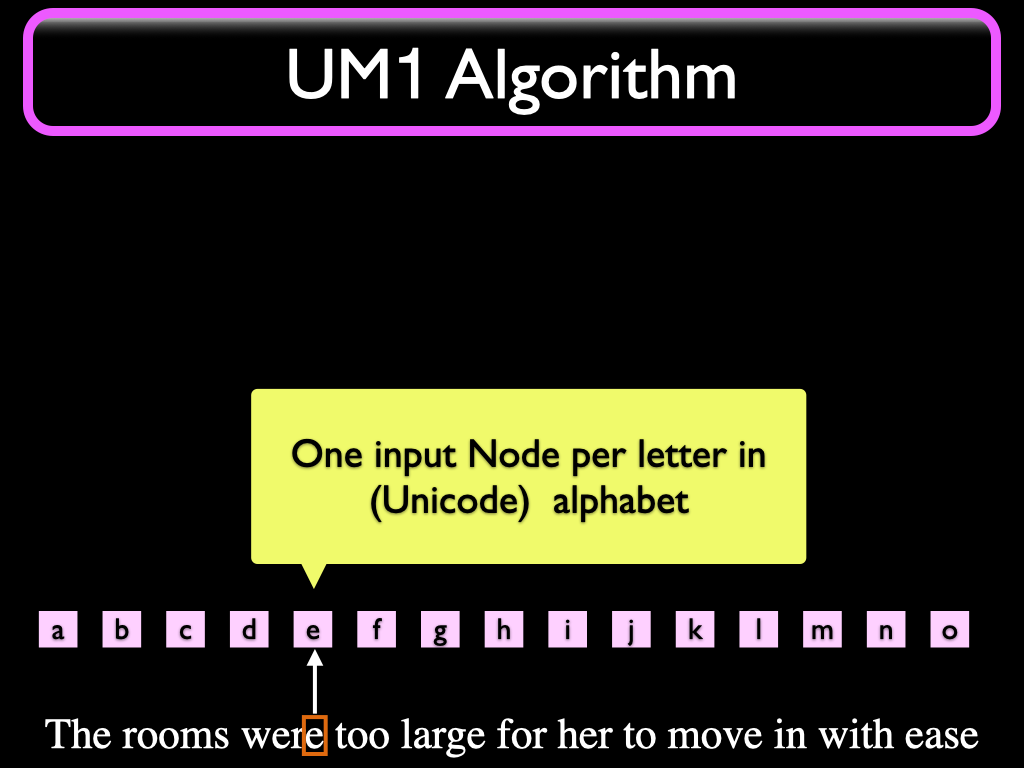
The letter currently being read is looked up in an "Alphabet" Map (a table) that binds each different UNICODE input character to a specific Node in the Understander. We call these "Input Nodes". When a character is read, the framework will originate an initial "signal" that is sent to the Input Node bound to that character. Note that except for debugging purposes and (future) language generation purposes, the character we just read can now be discarded. As Friedrich Hayek said, in the brain there is no vision, no sound, no touch. There is just neurons signaling neurons; same thing in an OL or UM1 system. Retinal neurons could be said to correspond to the Input Nodes in OL and UM1.
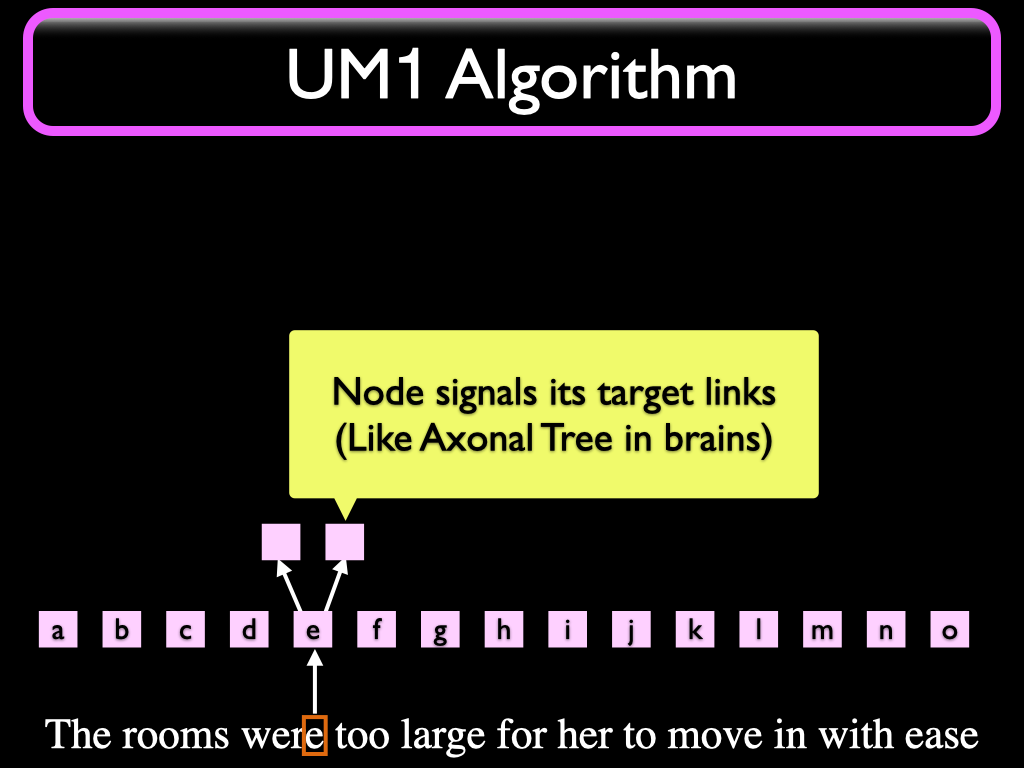
The Input Node then propagates the signal to other Nodes connected to it with outgoing synapse-like links. This is similar to a Neuron in a brain signaling its axonal tree.
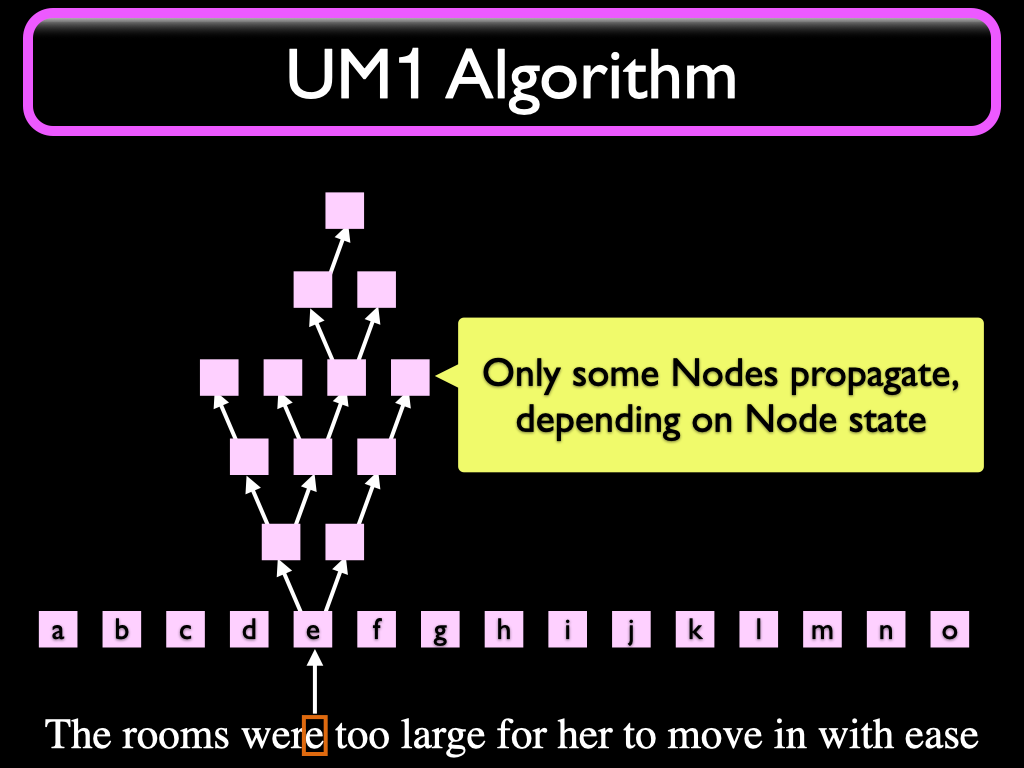
Some of these signaled Nodes propagate the signal to their outgoing target links, depending on conditions.
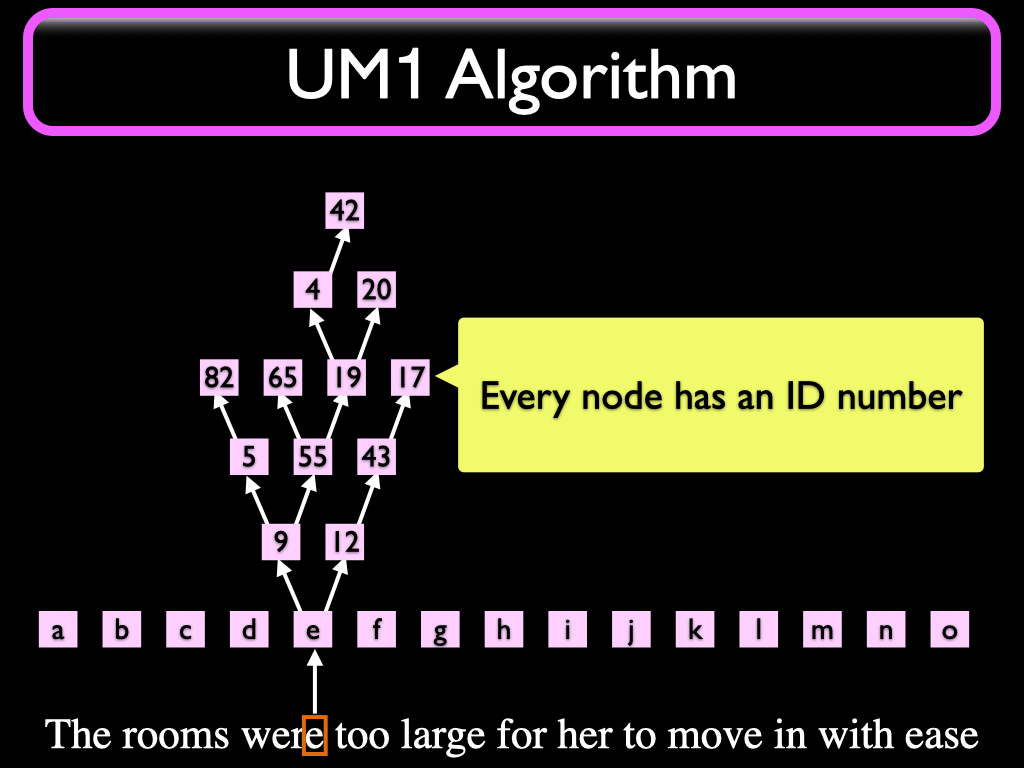
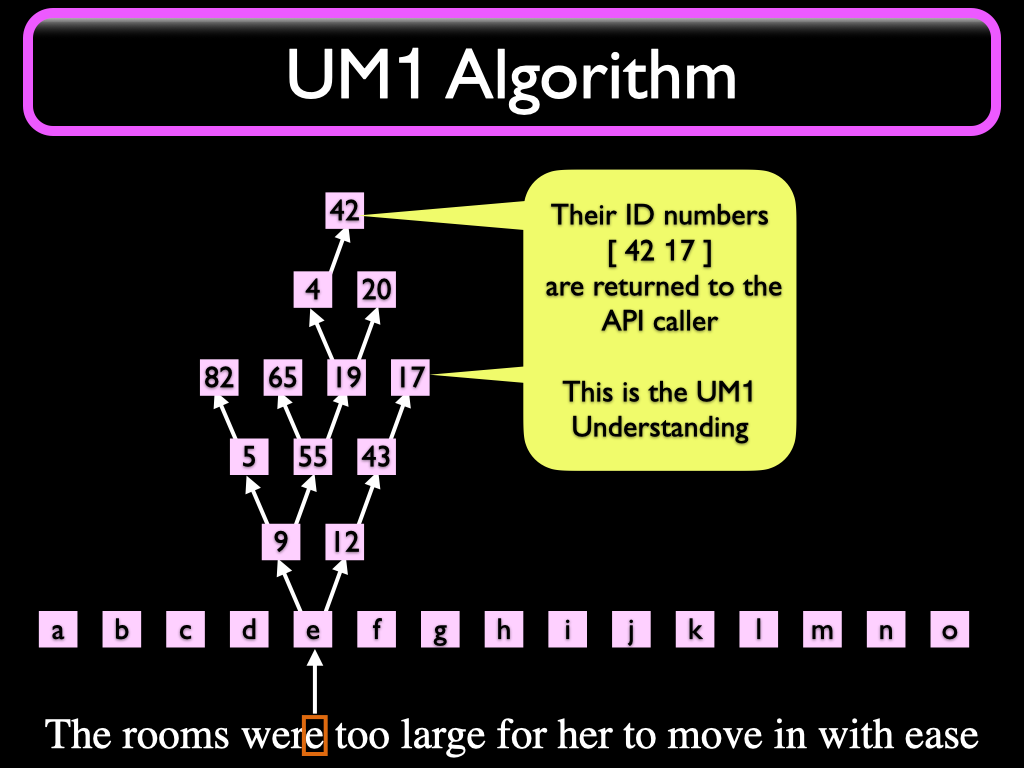
Every Node in the system is born with a unique ID number.
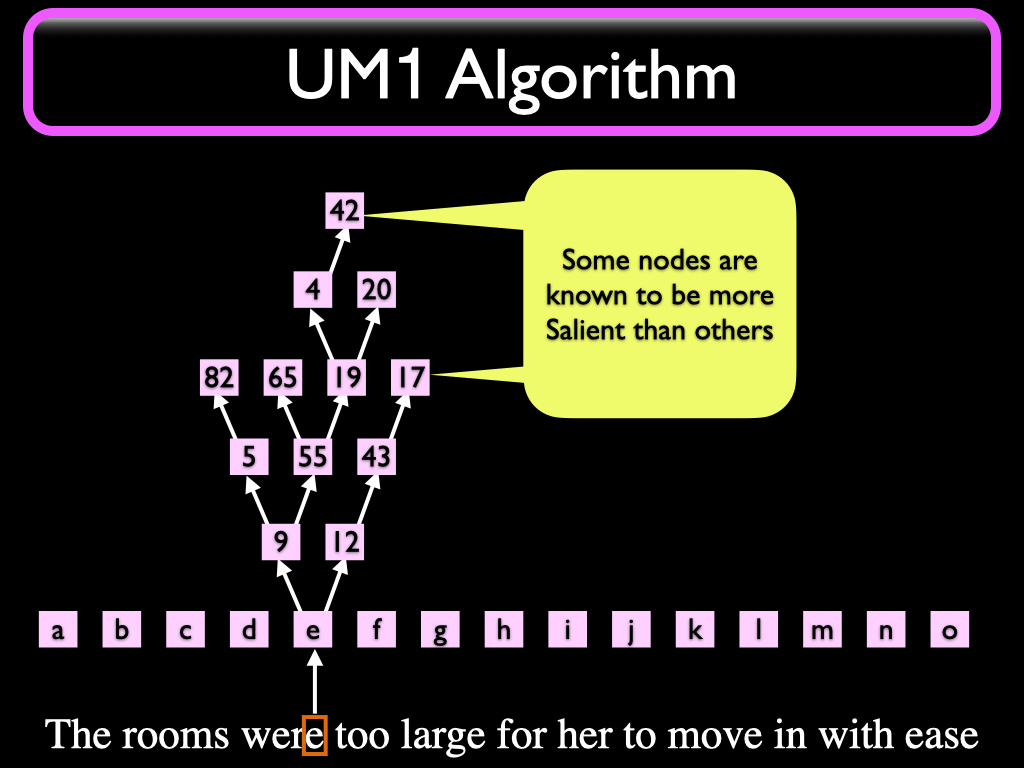
Some Nodes are known to be more important (Salient) than others. The ID numbers of these Nodes are returned to the caller in a list. After Understanding the whole message, the list will contain all Salient Nodes that propagated.
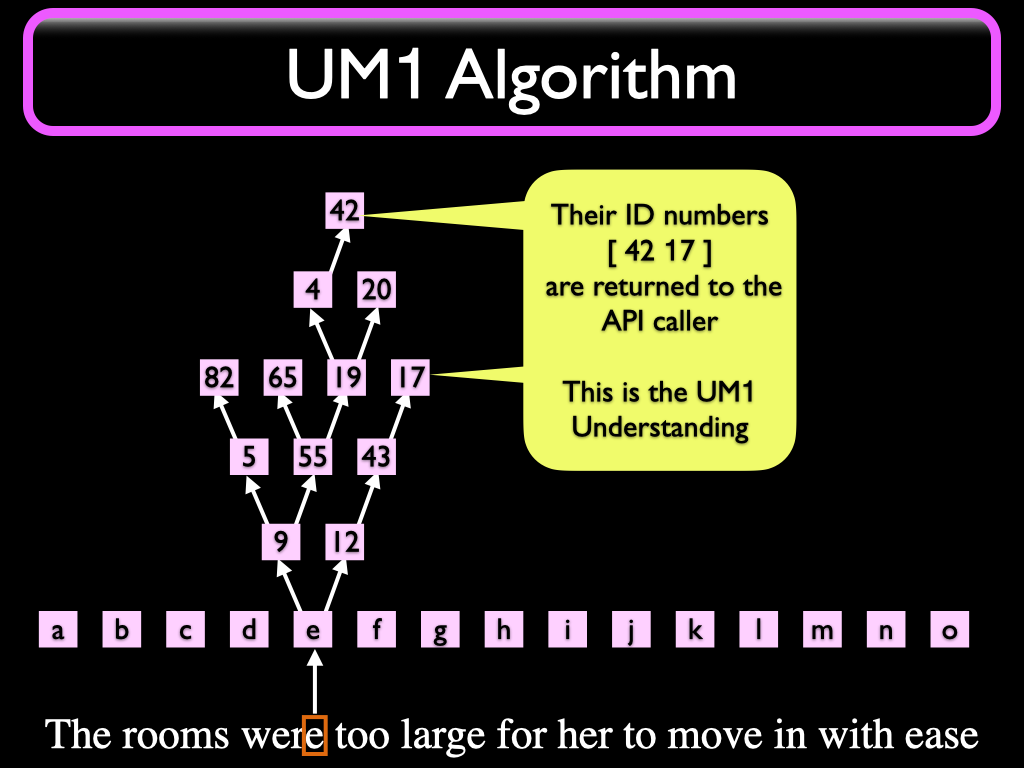
The list of ID Numbers is the Understanding you get from UM1. We call this "The Numbered Neuron API" and the resulting list is called a "moniform". It deserves a special name because in production environments the moniform is more complex than a simple list; it may contain annotations like meta-information and structure information such as chapter, page, line numbers etc.
We are not using any tagged learning material, just plain UNICODE text files. This is an enormous advantage over supervised learning, because well tagged text is expensive. The reason we can do this is that each Node (Concept) in the system is automatically given a unique tag – an ID number.
These ID numbers are opaque to the client. This is not a problem.
To find all documents on topic X, start with submitting one or more samples of topic X. If you want to detect the meaning of "I would like to know the balance in my checking account" in some tellerbot you are writing, then you can send that phrase as a topic-centroid-defining "Canonical Probe Phrase" to UM1 and save the resulting moniform in a table. The value in the "right hand column" in the table could be a token such as "#CHECKINGBALANCE" to use subsequently in Reductionist code, such as in a surrounding banking system.
UM1 is not a transformer; it can be described as a half-transformer, an encoder that encodes its understanding of incoming text as lists of numbers. The table of moniforms you build up when starting the client system will be used to decode the meaning. This is done entirely in the client end, in code you need to write or download.
To decode the Understanding received after sending UM1 a wild sentence (chatbot user input, a tweet to classify, etc) your client code will compare the numbers in the wild reply moniform to the numbers of all the moniforms in the probe table we built when we started, using Jaccard Similarity as the distance measure. The probe sentence that has the best matching moniform is the one we will say has semantics closest to the wild sentence.
Jaccard Distance tells how closely related two sets of items are by computing the set intersection and the set union between two sets A and B. The distance is computed by dividing the number of common elements (the intersection) by the total number of elements in either set. This provides a well behaved distance metric in the interval [0..1] as a floating point value. The canonical moniform with the highest Jaccard score is the best match.
In UM1, the ID numbers represent dimensions in a boolean semantic space. If the system has learned 20 million Nodes, each representing some identifiable language level concept, then we can view the numbers returned in the moniform as the dimension numbers of the dimensions which have the value "true". Consider a moniform that has 20 numbers (it varies by message length and input-to-corpus matchability) selected from a possible 20 million to get an idea of the size of the semantic space available to OL.
In some DL systems for language, concepts are represented by vectors of 512 floating-point numbers. In this 512-dimensional space, DL can perform vector addition and subtraction and perform amazing feats of semantic arithmetic, like discovering that KING - MALE + FEMALE = QUEEN. With boolean 0/1 dimensions, closeness in the semantic space becomes a problem of matching up the nonzero dimensions, which is why Jaccard distance works so well.
Traditional NLP is often done as a pipeline of processing modules providing streaming functions to do word scanning, lowercasing, stemming, grammar based parsing, synonym expansion, dictionary lookup, and other such techniques. When using UM1 you do not have to do any of those things; just send in the text.
Note that UM1 does not do any of those operations either. It just reads and Understands. And because OL learned the morphology (such as plural-s on English words) used by UM1, the system can be expected to work in any other learned language, even if morphology is different.
You can test UM1 yourself
A running UM1 is available for Alpha testing in the cloud. Test code (and perhaps python samples) are available for download at https://github.com/syntience-inc/um1 . Instructions are available in repository.
UM1 is not intended for production use. Syntience does not provide any uptime guarantees. Also, being a demo system, it is not configured to scale very far. If you want to use UM1 for business, contact sales@syntience.com and we will provide a dedicated server as a subscription service. But anyone can use it to evaluate UM1 capabilities at this early stage.