8. Organic Learning
An Evolution Based Alternative to Deep Learning for Natural Languages that can learn a useful amount of any language on the planet in five minutes on a laptop

An Evolution Based Machine Learning Algorithm
for Natural Language Understanding.
Introduction
I have (along with other researchers at Syntience Inc) been researching Deep Neural Networks of my own design since Jan 1, 2001. We made a major breakthrough in summer of 2017 and are now seeking to productize a Cloud Microservice for for Natural Language Understanding called UM1.
This post provides an overview of the ML algorithm used, which is called Organic Learning. A separate and detailed description of UM1, including links to downloadable test code, is available in Chapter 9. Understanding Machine One. The test code is written in python, but the UM1 service can be called from any language.
An Understanding Machine is not an Artificial Intelligence; Intelligence requires both Understanding and Reasoning. Reasoning is simply not part of the design; Organic Learning only learns to Understand language, not to Reason about it.
And UM1 is, as the name implies, a pure Understanding-Only Machine, not even capable of learning. It is also safe; the Understanding it outputs is the total impact it can have on the world. Further, everything at the algorithm level is fixed; it is a read-only system and can not learn or improve between updated release versions, which is important for repeatability.
On the other hand, it is fully general in the “AGL” sense: It can (“at the factory” at Syntience Inc) learn any human language by just reading online books in that language. And it may well Understand many things beyond mere language. Future testing will determine how much of the World (as described in the books it reads) the system is capable of Understanding by reading. And it may come as a surprise to some that Understanding is what a brain spends over 99% of its cycles on. It is the central problem in AI, and we cannot move on to Reasoning until we get Understanding right. Because you cannot Reason about that which you do not Understand.
And as you will see in the next chapter, the API for UM1 is very easy to use. No linear algebra will be required. Some set theory would be useful, especially the Jaccard distance metric. Programmers capable of modifying a working python example should be able to add these capabilities to their apps no matter what programming language they are currently using.
Problem Statement
Traditional Natural Language Processing (NLP) methods can perform many filtering and classification tasks but these algorithms, being Reductionist and statistical, cannot cross the syntax-to-semantics gap that would provide actual language Understanding. Many NLP algorithms rely on statistical Models and – as all Reductionist strategies tend to do – discard too much context too early. Neural networks, in contrast, exploit such contexts.
Deep Learning (DL) can now reliably identify objects in an image understanding situation and have made inroads into language Understanding, including semantics. But DL really is a poor fit for natural languages. Some results are impressive, such as DL based language translation and the amusing confabulations spewed by GPT/3 . DL algorithms used are computationally expensive, which is justified for image understanding. But language is linear and correlation discovery is a simple lookup in a reasonably recent past (instead of a convolution in a 2D image space, or worse). This means much more effective correlation discovery and Epistemic Reduction algorithms are available for text than for images.
The “Generalization Gap”, or sometimes, the “Semantic Gap”, is the step from syntax to semantics, from text to understanding, and is the single major hurdle to computer based Understanding of languages, and therefore, to understanding of the world. Some people still doubt that Deep Learning can bridge this gap for languages. But I think that most kinds of DNN systems are capable of this and will provide bona fide human-like (but not necessarily human-level) language Understanding.
If some company already has an existing NLP (Reductionist, Language Model Based) solution to a problem, why would they consider switching to NLU? Because they may need to handle things that word and grammar based systems cannot really handle or even identify without much effort and expense, such as
- Hypotheticals
- Negations
- Questions
- Irony and satire
- Pronouns and other co-references
- Free form social noise like greetings
- Non sequiturs
- Rhetorical questions
- Nested sentence structures
- Unexpected out-of-domain words
- Foreign language words and phrases
- Colloquial, truncated or abbreviated phrases
Skills in these matters can now be learned much easier than they could be analyzed and then programmed. And to do it in more languages, just learn more of them.
Definitions
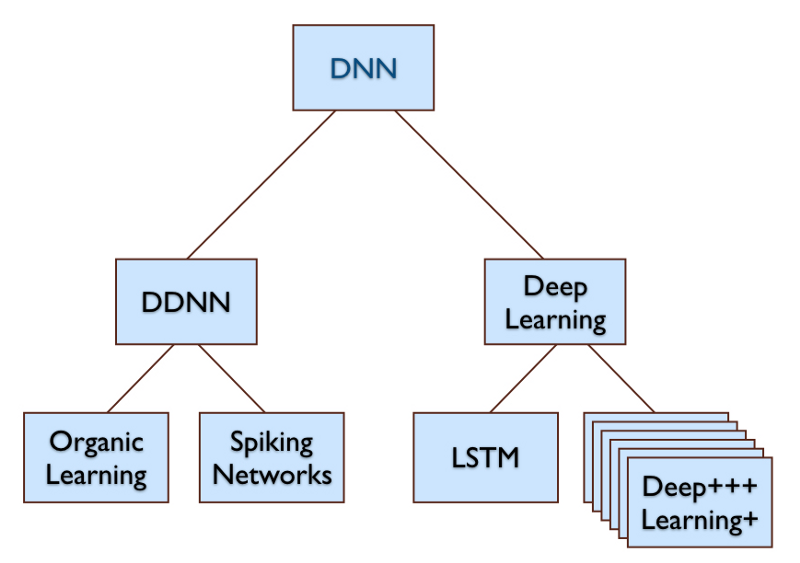
A Deep Discrete Neuron Network (DDNN) is a Deep Neural Network (DNN) that uses software simulations of discrete neurons interconnected with explicit neuron-to-neuron synapse-like links. In contrast, Neural Networks used in Deep Learning use linear algebra style operations on arrays of floating point numbers. These representations are not isomorphic in spite of some claims to the opposite.
In what follows, I will use the term Deep Learning or “DL” to describe the family of hundreds of Deep Neural Network algorithms inspired by (and building on) the work of LeCun, Hinton, Bengio, Schmidhuber, Ng, Dean, et al. As the diagram above shows, both DL and DDNNs are DNNs.
DDNNs have been studied before; they are much more brain-like than DL based systems and therefore a plausible first attempt by researchers who approach DNNs from a neuroscience angle. But the resulting systems have so far not been able to compete with other methods, including DL, on useful tasks. These failures can be attributed exactly to the same reasons Deep Learning for image Understanding didn’t work until 2012: Our machines were too small and too weak, and our training corpora were too small. Some algorithmic and Epistemological confusions also prevented Epistemic Reduction from working in these early attempts.
DL was the first DNN that worked. It is not the only one. We can finally create and use Deep Discrete Neuron Networks, because our computers are now up to the task.
Advantages of Organic Learning
Organic Learning is well positioned to replace Deep Learning (DL) in natural language domains.
- OL was explicitly designed for sequential data like text, voice, or DNA.
DL was designed to understand images and its use for text is a poor fit. - OL requires 5-6 orders of magnitude less computation and less energy than DL for NLU.
- OL does not require (and cannot even benefit from) a GPU, T-Chip, or other special hardware. Conventional von Neumann architectures work best. Specifically, there is no need for any kind of "active memory" or "memory based computation" or other forms of "per-neuron" parallelism.
- OL learns in a fraction of the learning time required in DL based language understanding. Minutes on a single thread on a laptop rather than days using hundreds of GPU based hosts in a cloud. Learning is effective with much smaller corpora than those used in DL, as long as SOTA accuracy is not a design requirement.
- OL is capable of unsupervised learning of any language given nothing more than plain (untagged) text in that language .
- OL scales as needed. The only limit is the size of main memory.
- OL inference (runtime) engine (UM1) requires much less memory.
- OL runtime clients require no end-user programming in TensorFlow, Keras, or other ML languages. Python sample code is available.
Connectome Algorithms
The learner starts out empty and then learns recurring sequential patterns it discovers in its input stream. The learning algorithm slowly builds a Connectome, a graph of Nodes and Links (like neurons and synapses) to reify the experiences.
The framework provides direct Java level access to the learned connectome and its individual neurons and can be directly used for Epistemology level experiments. Clients will not have access to this, but researchers at Syntience benefit from this as implementers. We call the results of programming at this Meta-learning-level "Connectome Algorithms"
We have a "Clojure REPL" running in the same JVM that is accessed asynchronously from an outside Emacs editor using an API. We can interactively conduct experiments in Clojure (a LISP) on the Connectome. Most of these involve graph traversal to discover concept correlations.
Potential
It is worth emphasizing that OL is not an incremental improvement on Deep Learning. It is a completely novel capability, never seen before, with its own strengths, potential, and limitations. In patent language, it is a fruit of a different tree than DL, and was designed from the start using a Holistic Stance, as described in Chapter 7, The Red Pill of Machine Learning.
Because it is new, we have few clues about how to estimate its impact. We can foresee a range of future applications for general human language understanding by computers, even small and cheap ones. An algorithm for human-like (but not necessarily human-level) Natural Language Understanding – NLU(*), as opposed to NLP – such as Organic Learning, opens up what has been estimated to become a $1 Trillion NLU market out of a multi-Trillion general AI/ML market.
OL has been developed by 1-2 people and has worked only since 2017. In contrast, Deep Learning has benefited from thousands of researchers improving it since 2012. This is only the beginning for OL.
Towards voice input and output
OL and UM1 are text based. If we want voice input and output, then we can use speech-to-text and text-to-speech systems before and/or after OL or UM1. While useful, the main use of voice I/O will only be realized when we get decent ML based question answering systems, or better, systems that can handle "Contiguous Rolling Context Mixed Initiative Dialog". We are continuing research in this direction. OL could probably handle speech by learning from speech input like current ML based voice input systems but we have not researched this.
The unreasonable efficiency of Organic Learning
The OL and UM1 algorithms are very fast. Learning can stream, sustained, at 5,000 cps per thread, and Understanding has been run at 100,000 cps per thread on a laptop. Deep Learning based NLU projects like BERT and GPT/3 take months to learn in the cloud. Their results are not directly comparable to OL but either strategy may work in any specific application and should be evaluated on a case by case basis. The energy savings alone make a compelling argument for using OL.
Learning is thread-safe. In a 200 thread machine, the system could be reading from 200 different text files, such as different pages in Wikipedia, simultaneously, into the same global RAM image of Nodes and Links. This would be like having one single brain and 200 pairs of eyes reading books.
There are entire classes of applications that could use the "Industry strength Understanding" provided by OL. It may not beat State of the Art in academia, but it can be used with very little API programming effort and has a shallow learning curve for humans. We also expect OL to handle multiple languages well, and it might compete well on price because of energy and compute savings. A cloud based microservice could handle this for any kind of agent, such as language based phone apps.
Designed for Sequence Processing
Convolution of images in DL for the purpose of correlation discovery is expensive. When Understanding language, we still require correlation discovery, but text is linear and this operation becomes a much simpler problem in the time/sequence domain rather than (as in DL) in a 2D/3D/4D image/movie/point cloud domain. In effect, all correlations in text are references to something experienced in the past, and the past is linear, searchable and indexable. This, and the next paragraphs, explain the amazing learning speed of Organic Learning.
Only Activate Relevant Concepts
In OL, unless we are reading about, say, a potato harvest, there is no reason to touch any of the software neurons involved in “representing” potato harvests. So we can have billions of learned concepts just sitting quietly in main memory, consuming no CPU cycles, until “their topic” is discussed. They activate, make a contribution to understanding, disambiguation, and learning, and they may even may learn something themselves. They then return to dormancy until next time the topic is discussed. This is a major advantage of discrete-neuron strategies.
Therefore, OL systems do not require explicit attention controlling mechanisms. Focus emerges from matches between the global gathered experience and the concepts discovered in the text in the input stream.
In contrast, in DL, every pixel of a processed image is pushed through the entire GPU processing stack many times. And each layer does some moderately expensive array arithmetic, which is why using GPUs is so important in DL.
Track Correlations Explicitly
One of the main operations in Deep Learning is correlation discovery by convolution of images in multiple layers. This is done in the upward pass. The discovered correlations are used to somewhat adjust the weights of the DL network in the Stochastic Gradient Descent downward pass. Because of this, the network has changed, necessitating another upward pass of convolutions through the entire stack, until there is sufficient convergence.
In contrast, in Organic Learning, when the algorithm discovers a correlation it simply inserts a Synapse-like link to represent that correlation. Being an evolutionary system, the correlation will remain as long as it contributes to correct Understanding but will be removed in a Darwinian competition if it doesn’t contribute to positive results. These mostly-persistent Synapse-based correlations make re-convolution unnecessary. Do it once, and it's done.
Neural Darwinism = RL + Sex
The idea of Neural Darwinism is that in brains, from millisecond to millisecond, there is a continuous battle for relevance among ideas. The ideas are evaluated for fit to both the current sensory input and the totality of gathered experience that has been reified in the Connectome.
Those parts of the Connectome that assist in providing a good outcome are rewarded and other parts may be punished. This is Reinforcement Learning (RL).
In a Neural Darwinism based Machine Learning system the best ideas get to breed with other good ideas, occasionally producing even better ideas. This is how we can generate ideas that are better, often in the meaning of "better abstractions", than any of the ideas we started with. This is the reason sexual reproduction speeds up evolution so much, in nature and in our algorithms spaces. It allows multiple independently discovered inventions to merge into one individual – a fact that is often neglected in naïve discussions about the effectiveness of Evolutionary Computation.
Evolution is perceived as slow because evolution in nature takes a lot of time. But computers can evolve populations of thousands of individuals in milliseconds, and Genetic Algorithms, when done right and attacking a problem in a suitable problem domain, are very competitive and are much faster than their reputation.
Character based input
An OL system does not require the input to be parsed into words; it reads text character by character which means it can also learn languages that do not use segmented (space separated) words, such as Chinese. Each character read from the input activates a “character input neuron” that then signals other neurons, etc., and this cascade of signaling is what determines both what the sentence means and whether and where to attach any new understanding learned from that character, given the past, up to that point, as context. This incremental attachment operation is what provides the “Organic Growth”.
Flexibility and Code Size
OL is a simple java program, about 4000 lines of code for the learning algorithm itself. Add three times that for debugging, visualization, APIs, and test framework. The core algorithm exists in two versions: Learning (Organic Learning Learner) and Runtime (Understanding Machine One – UM1). Learning, all told, is about 16,000 lines. The UM1 code is about 1,700 lines, of which about 500 lines implement the main algorithm. Um1 only imports I/O and Collection classes.
The learner creates, as its main output, a file containing a “node wiring list" describing which neurons connect to which other neurons. Such a Competence Creation event is typically scheduled after each 10 million characters of corpus have been read. Given a Competence file name, UM1 loads that list and re-creates the learned neural structure and then uses that as the basis of its Natural Language Understanding Service.
The learner is currently kept as a trade secret. The UM1 runtime can be source licensed to customers since it does not contain any of the learning code. But initially UM1 will only be available as our cloud based MicroService.
The OL Learner can also be saved in a full Java image format which can be re-started later to continue learning. This means any learned skill can be used as a base for further learned skills. After learning Basic English, we can top it off with Medical English and Business English, targeted at different application domains.
Test Strategies
We have used many different tests of language understanding competence for this research but the strategy described in Noah Smith’s paper “Adversarial Evaluation for Models of Natural Language” is our favorite. We think our tests are closer to capturing Understanding than most NLP era tests; it can be made more or less difficult by choosing more subtle distinctions between the test cases; They are easy to understand, quick to execute, and can be adopted to many situations. We can execute these tests asynchronously at regular intervals such as after each 1 million characters of corpus. We designed the system to not be able to learn from its test data.
NLP era test cases emphasize Reasoning and various puzzles, which require cognitive capabilities that we decided to not even try to implement until we have productized our 100% pure Understanding systems. As a consequence, we cannot currently beat state of the art at GLUE or SUPERGLUE.
Demonstration of Learning English
The Organic Learning algorithm can learn a useful amount of any language on the planet in five minutes running on an old Mac laptop. With "useful amount" I mean that the system could be used for "industrial strength" Understanding, such as in a chatbot. Of course, as is common in Machine Learning situations, learning overnight or even for a few days will continue to improve the results.
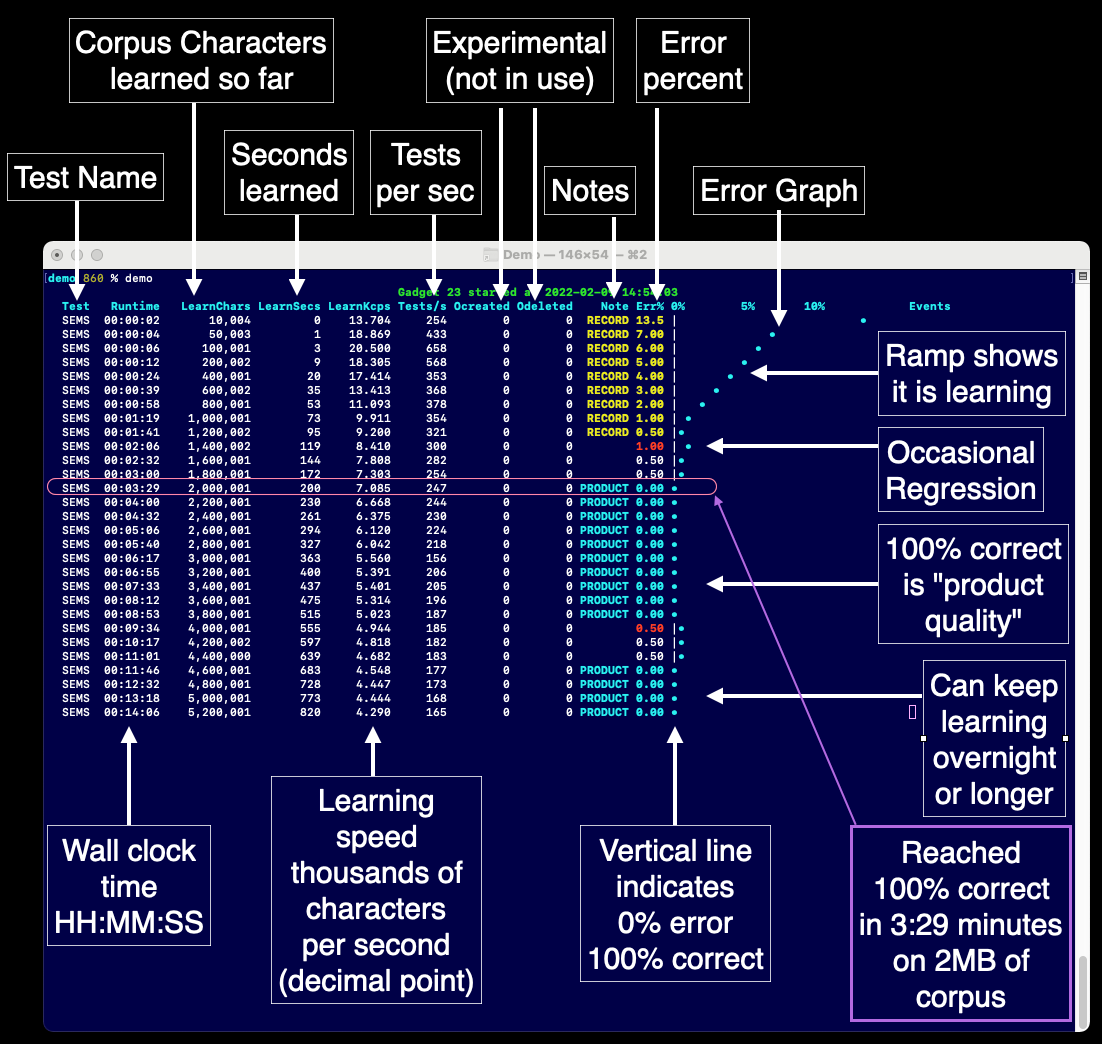
Below is an annotated screenshot of our demo of the system learning English from scratch. This demo is running code from December 2019.
You can inspect the test file we used. Download it here. The system cannot learn from tests, which is why we can run it as often as we want.
We can demonstrate this live, in person or in Zoom. Or you can watch this movie: