6. Experimental Epistemology for AI
We can now create computer based experimental implementations to Epistemology-level theories in order to test them and learn from the outcomes

Experimental epistemology is the use of the experimental methods of the cognitive sciences to shed light on debates within epistemology, the philosophical study of knowledge and rationally justified belief. Some skeptics contend that ‘experimental epistemology’ (or ‘experimental philosophy’ more generally) is an oxymoron. If you are doing experiments, they say, you are not doing philosophy. You are doing psychology or some other scientific activity. It is true that the part of experimental philosophy that is devoted to carrying out experiments and performing statistical analyses on the data obtained is primarily a scientific rather than a philosophical activity. However, because the experiments are designed to shed light on debates within philosophy, the experiments themselves grow out of mainstream philosophical debate and their results are injected back into the debate, with an eye to moving the debate forward. This part of experimental philosophy is indeed philosophy—not philosophy as usual perhaps, but philosophy nonetheless.
Experimental Epistemology by James R. Beebe
Traditional Experimental Epistemology conducted experiments on interviews and psychological tests on human volunteers or relied on population statistics.
As one of the newer branches of Cognitive Science, Machine Learning has now provided us with a very different approach to this domain. We can now create computer based experimental implementations to Epistemology-level theories in order to test them and learn from the outcomes.
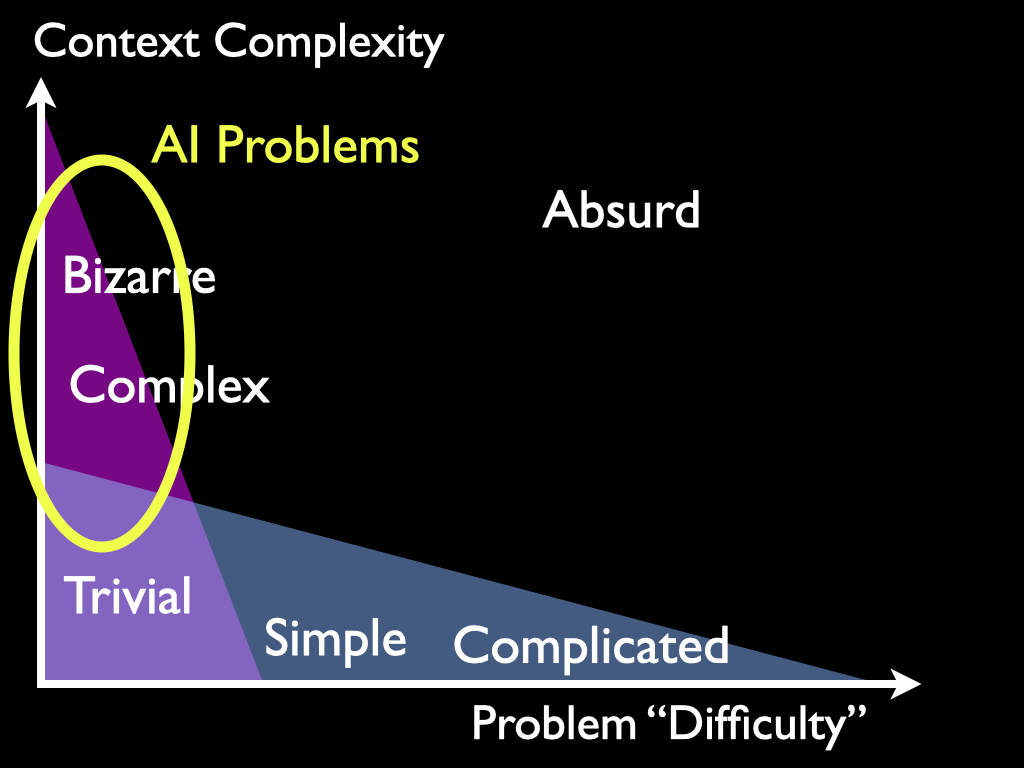
In Machine Learning, the most important Epistemology level concepts and hypotheses are about Reasoning, Understanding, Learning, Epistemic Reduction, Abstraction, Creativity, Prediction, Attention, Instincts, Intuitions, Concepts, Saliency, Models, Reductionism, Holism, and other things all sharing these features:
- Science has no equations, formulas, or other Models for how they work. They are Epistemology level concepts, not Science level concepts.
- Our theories about these concepts have to be sufficiently solid and detailed to allow for computer implementations.
This is because Science itself is built on top of Epistemology level concepts. And practitioners need to be aware of this or they will experience cognitive dissonance induced confusion and stress.
The Red Pill of Machine Learning confronts the Elephant in the Room of Machine Learning: Machine Learning is not Scientific.
What Can We Learn from AI Epistemology?
An excerpt from The Red Pill:
Consider the below statements from the domain of Epistemology, and how each of them can be viewed as an implementation hint for AI designers. We are already able to measure their effects on system competence.
"You can only learn that which you already almost know" -- Patrick Winston, MIT
"All intelligences are fallible" -- Monica Anderson
"In order to detect that something is new you need to recognize everything old" -- Monica Anderson
"You cannot Reason about that which you do not Understand" -- Monica Anderson
"You are known by the company you keep" -- Simple version of Yoneda Lemma from Category Theory and the justification for embeddings in Deep Learning
"All useful novelty in the universe is due to processes of variation and selection" -- The Selectionist manifesto. Selectionism is the generalization of Darwinism. This is why Genetic Algorithms work.
Science "has no equations" for concepts like Understanding, Reasoning, Learning, Abstraction, or Modeling since they are all Epistemology level concepts. We cannot even start using Science until we have decided what Model to use. We must use our experience to perform Epistemic Reductions, discarding the irrelevant, starting from a messy real world problem situation until we are left with a scientific Model we can use, such as an equation. The focus in AI research should be on exactly how we can get our machines to perform this pre-scientific Epistemic Reduction by themselves.
And the answer to that can not be found inside of science.